
This summer, I was fortunate enough to get the chance to work on a project as part of the Summer of Haskell. This allowed me to work on the TidalCycles (Tidal) live coding software: free/open source software for pattern generation with code. Often this is used to create musical pattern, although increasingly it has been used for other things too, e.g. pattern visualisation, weaving. It is a language that is regularly used in live coding, a subset of artistic programming which looks at live improvisation and performance of algorithms to produce artistic outputs such as music, visuals or dance (to name a few).
I was mentored for this project by Alex McLean, the creator of TidalCycles and was provided with some real insight into the innards of the software. I’ve also been making and performing music with TidalCycles myself for a little while now (since around 2017) and so I’ve come to know it well enough, and have in the past looked at ways to shape it around my own practice. As TidalCycles is a domain-specific language embedded in the functional language of Haskell, it makes writing functions on the fly a possibility for people wanting to customise their own pattern creation, if they have the time and interest to get into the Haskell side.
In this project, I wanted to both expand TidalCycles in new directions and tie it in with the work that I am currently doing on my own PhD based in computational creativity. My initial project proposal aimed to tie these together, whilst trying to learn some Haskell too by perhaps leveraging existing Haskell libraries.
Why create an autonomous live code agent? Why use Tidal?
Machine Learning models tend to deal with processes that are static. Typical symbolic representations are in MIDI format (which in itself is quite a limiting representation of musical content, usually reducing the complexities of music to only pitch number and velocity and therefore losing a lot of nuance around timbre and expression). Moreover, most are trained on scores of musical information: pieces in which the outcome has already been predetermined (usually by a composer). Machine Learning of Indeterminate Music is also an area that has been underexplored, perhaps due to the complexities that arise, however Tidal could be a particularly useful software to explore these ideas.
How do we want autonomous agents to behave?
One of the first things we considered was the behaviour of our autonomous coder- how do we want it to behave and, maybe more importantly, how do we want to interact with it? Is it going to be standalone "intelligent" agent (musical intelligence would, arguably, have to include a strong focus on emotional intelligence) or is it augmenting the work of the live coder? How much autonomy can we (and do we want to) give it? Something that was also discussed was whether the agent would behave constructively or destructively? Arguably, both are equally valid forms of creative input and the latter presents an interesting challenge too: most computationally creative systems tend only to focus on the creation of new material. But, depending on our definition of human creativity, can we posit destruction as a form of creativity too?
About the project
The initial project proposal submitted in April 2020 looked at creating functional machine learning algorithms in the Haskell language for autonomous generation of new, syntactically correct Tidal Code. Hasktorch is an ongoing project that aims to leverage the core C++ libraries shared by PyTorch for ML/neural network architectures written using Haskell. Although this might be useful in future iterations of the project, the work ended up moving away from this, partly due to the challenge of having to implement a new NN architecture for this specific project, which seemed a little out of scope for a three month project.
To initiate this project, my mentor Alex also put me in touch with members of the community who were already working on similar projects during the community bonding period. This allowed me to reach out to others who were working in the area already, as there have been a few projects that have attempted to tackle this problem. I also started the Summer of Code by seeing what other things had been going on in the area by posting a thread on the TidalCycles forum. This flagged a few various interesting things, including an autonomous agent in Python using sequence-to-sequence neural network algorithm to autonomously generate Tidal Code and grammar-based agents, such as this auto-evaluating autonomous coding agent or evolutionary-based algorithms for autonomous code generation.
Tidal Development
Getting involved in the open source development of TidalCycles was one of the first things that I did during the summer of code, allowing me to understand more about both the contribution process and the innards of how TidalCycles applies the Haskell type system to represent the generation of patterns. I worked on fixing a couple of issues, like altering and adding new functions for better representations of an existing function, working on running tests for functions and changing the input type for other functions.
Further to this, I started working with my mentor on some work on development of a Tidal API. This was an experimental project that was creating a Haskell-based listener and receiver for interacting with Tidal. This followed the need to support messages sent between Tidal and autonomous agents running in a different process and/or language, but turned out to also be useful for human user interaction, allowing more feedback between user and software. For example, the user could run code and error check (where > represents an outgoing message and < an incoming message):
> /code <id> <source>
< /code/ok
expand the notation into a different format (e.g. from Tidal’s “mininotation” to Haskell):
> /expand <code>
< /expand/ok <expanded code>
or get the cycles per second value
> /cps
< /cps <number>
Autocompleter
As the work previously mentioned by Stewart et al. seemed particularly close to what I was initially proposing for the Summer of Code, we got in contact with them to arrange a few meetings to discuss any areas of overlap and potential collaborations. Their work however looked at building the architecture within Python, leveraging the tensorflow library and neural nets used commonly for speech translation problems. Rather than simply attempt the problem again within Haskell, we decided to alter some of this brief, perhaps looking to see how we could leverage some of their work to build a creativity support tool for Tidal users looking for some creative inspiration. The idea that came from discussions was building an "autocomplete" agent, one that could take an incomplete string of TidalCycles code and return suggestions of functions or parameters
Leveraging the existing work done by Stewart and Lawson meant adapting some of the code for use in an autocomplete agent became part of the scope of this work. To do so, in collaboration with the other researchers, we ended up building a repository for the two-way communication between the machine learning agent in python and the atom editor commonly used for evaluating TidalCode. This was done building a node server in atom and a mock python server, and hot key evaluation to select certain lines/words from the editor and send to the python server.
As the auto-completer’s ML backend was running in Python and we were sending OSC messages between a test python server and currently only an atom editor, the earlier discussed Tidal API would attempt to make this interaction more transparent and universal.
Tidal Walker
One issue flagged with the autocomplete agent was the nature of the corpus used for generation of new pattern, based on the code of a small set of live-coders. This would be able to create ‘statistically probable’ code, which might not have been seen before but would be unlikely to introduce radically new ideas. We wanted a way to expand the ‘search space’ of the machine learning agent, by adding combinations of functions to the corpus that had not been seen before.
This led to a related work that used random walks, Haskell’s strict type-checking system and n-gram models from a corpus of existing patterns, to create a potentially infinite number of possible Tidal patterns. The ‘walker’ takes a haskell type signature as a target – in this case a pattern of synthesiser control messages, and chooses a function that can ultimately produce that target. It then recursively fills in any missing arguments of that function. This takes account of partial evaluation, and the specialisation of polymorphic types as arguments as they are applied.
The aim was to create a walker agent that could navigate through the conceptual space of all possible Tidal code, modelling Haskell’s type system to ensure anything generated would be syntactically valid. To ‘steer’ this walk, we weighted its decisions based on n-gram data, created realistic code that could then be used to train the autocomplete agent. There were various steps taken to implement this. Below shows the architecture of such a program.
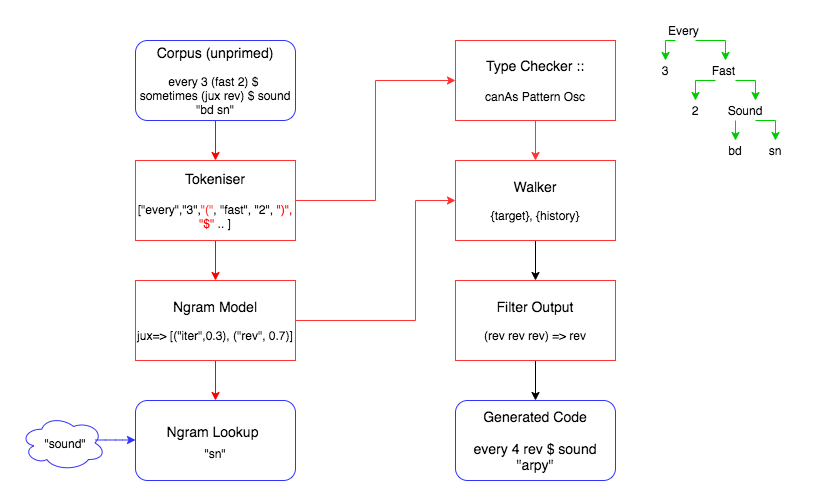
Tokenising Code
One of the first things that had to be done to achieve this was to correctly tokenise the patterns for the ngrams to be generated upon. The tokenisation process is described as below, with various functions having been written in Haskell to achieve the various steps.
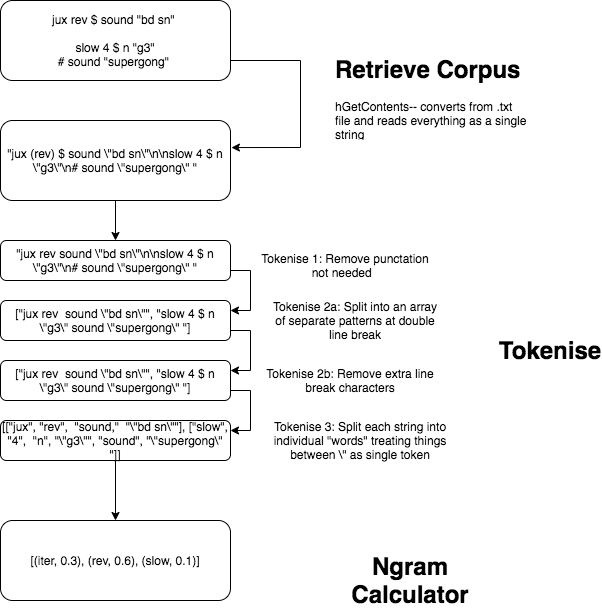
Calculating Ngrams on Data
Once the dataset was correctly tokenised, it ended up being used to create the weightings for the ngram walker as follows. The tokenised code is then imported into a separate Haskell module, the frequency of ngrams is generated by calculating the frequency of occurrence of n-pairs of functions in the tokenised data. From the frequency distribution of n-pairs of consecutive functions, this can then sort these into a data structure that can be accessed later on by the walker to calculate the associated transition probabilities.
Weighted Walking for Unique Outputs.
Once the code has been tokenised and analysed, it can be used by a walking agent to generate new sequences of syntactically correct code. The inherent type signature structures are used as a framework for generating all the possible options that can occur after an initial function is chosen at random, thus ensuring the final code output generated can be evaluated. The weightings are then applied to their corresponding potential next functions in the sequence given the current function is known from the ngram data structure (this is applied as a Maybe value to denote that values are optional as there may not be some corresponding values from the dataset for the set of all possible next functions).
A variable is also implemented that could be a user controlled feature of any further iterations of the project, called "adherence." This allows control over how the weightings are structured, whether they adhere to the corresponding dataset, especially wherein a "Nothing" data type is generated for functions that are possible but unlikely.
Future Works
Currently, the tokenisation is only working on the Haskell functions of the TidalCycles domain specific language. There is, however, another aspect to writing TidalCycles known as its mini-notation. In brief, the mininotation is a mini-language within Tidal, allowing polyrhythmic sequences to be efficiently expressed. They are denoted by overridden strings, which are parsed into Tidal patterns. At this stage of this project, these strings have been treated as single tokens. However, this does not capture the inherent structures from the mini-notation and future work should look at how to correctly tokenise and model these too. Perhaps one way around this would be in creating a function that could expand these mininotation expressions directly into executable Haskell code.
Furthermore, the ngram dataset at the moment is currently only generating bigrams (ngram where n=2) giving limited higher-order representation. E.g. the output of a bigrams might show the transition probabilities for functions as:
slow 8
whereas an ngram of higher order (n >2) gives a wider representation of what is happening in the pattern:
range 0.1 0.2 $ slow 8 $ sine
Similarly, other functions e.g. "weave" takes a high number of functions for achieving syntactical correctness which a bigram couldn’t directly capture. Furthermore, ngrams do not capture the hierarchical structure of a syntax tree – looking into applying hierarchical Markov models to the abstract syntax trees could be a better approach, and is also left for future work. Nonetheless, bigrams, in capturing the likelihood of two tokens appearing together, does appear to improve the overall coherence of the generated code.
Some of the issues encountered with the output of the walker’s generation were similar to problems encountered in genetic programming. One of these is the notion of bloat (i.e. where various functions are added together that end up cancelling each other out like a series of successive (+1) and (-1) functions). In the Tidal generation this occurs where a pattern could be reversed 2n or 2n+1 times and this would be the same as an identity or the reversed pattern. Another issue encountered was idempotent functions, (i.e. where f(f(x) = f(x)). This occurs in cases such as every 1 (f(x)), which means that the function would be applied as without the every. Creating a filter for these would increase the efficiency of outputted code.
Project Reflections
Other than achieving outcomes from the project, some of the main things I have learnt have been to do with collaborating on an open source project. Not coming from a traditional computer science background, this has been one of the first larger scale projects I’ve been able to work on (although what I do has meant I’ve learnt a lot of computer science over a short period of time, I still feel “new” to the area). Some things that have been particularly useful to learn are using github to collaborate on coding projects (and how to fix merge conflicts!) and on attempting to meet milestones throughout the project, including trying to organise these coherently.
One particular problem I encountered throughout was that most of my coding experience comes from imperative coding. This meant that when trying to write code in a functional way seemed a little unintuitive for me. It took some time to work on using concepts like folds and recursions rather than concepts like iterating over a for-loop. Learning Haskell through completing a project has definitely helped me think in a more functional way.
Finally of course, there were some errors that were encountered with the project. Debugging in Haskell was a little tricky without being able to backtrace/ find breakpoints in the code. Using a lot of print statements helped conceptualise how the program was running and where things might have been going wrong.
One thought on “Autonomous Live Coding: Summer of Haskell Project”